
ClearPoint Practice Lead – Data Engineering and Principal Engineer Asanka Padmakumara explores how DataOps concepts can be applied with Snowflake and DBT Cloud.
Developer Operations, better known as “DevOps”, involves providing infrastructure, support and processes around software engineering projects. Ultimately, the concept is a combination of practices that brings together development and IT operations to provide continuous delivery at velocity.
DevOps is not a new concept for the software development space; it has been in the landscape for a number of years helping software engineers increase efficiency, speed and security of software development and delivery. However, the uptake of DevOps concepts within the data engineering space has been slower.
Although data engineers are late to the party, applying DevOps concepts has recently become a must for data engineering projects – especially in enterprise-level data warehousing projects. When it comes to data engineering, the term DevOps changes to DataOps but similar concepts are applied. For DevOps, the focus is on code, whereas in DataOps, the focus is on data.
Two key platforms have emerged with the rise of DataOps, both becoming fast favourites. Snowflake has become well-known as a cloud-based data warehousing platform, growing in popularity due to the many powerful features that it offers.
DBT Cloud, a SQL-first transformation workflow, has become increasingly popular to implement the transformation layer in a data engineering project. The transformation layer is where all the heavy lifting takes place, which includes cleaning data, applying business logic and aggregations.
Snowflake and DBT Cloud work seamlessly together; with most DBT Cloud training materials created using Snowflake as the data platform. In this post, we will cover how DataOps concepts can be applied to a data engineering project when Snowflake and DBT Cloud are used within a project.
The following diagram is used by Snowflake to explain how the DataOps concepts work with Snowflake.
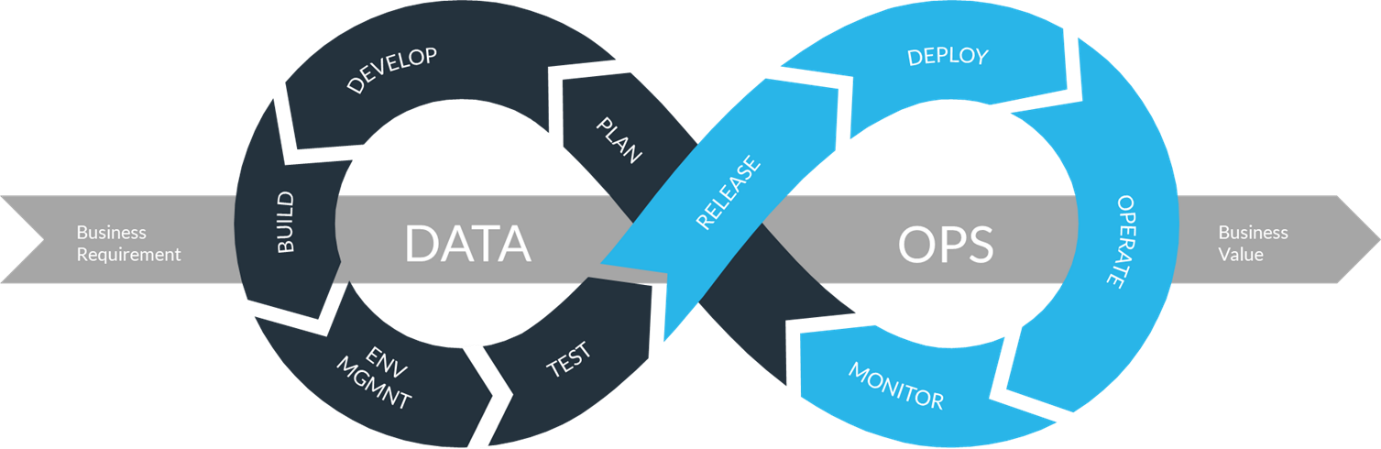
Plan
Planning is a key component in DataOps, irrespective of the delivery methodology used. Snowflake and DBT Cloud have no capabilities around planning. Therefore one would have to use tools such as Jira, Azure DevOps Boards and Asana boards to manage a project’s work backlogs and sprint planning.
Develop
In any data engineering project, ETL or ELT is the most time-consuming part. ETL and ELT stand for Extract Transform Load and Extract Load Transform respectively, which are techniques for implementing the processes around which data is taken from sources and transformed into a format where it is amenable to querying and analysis. Within this, the transformation implementation consumes the majority of the time. Tools such as Fivetran and Azure Data Factory have made the extraction and loading aspects relatively easy.
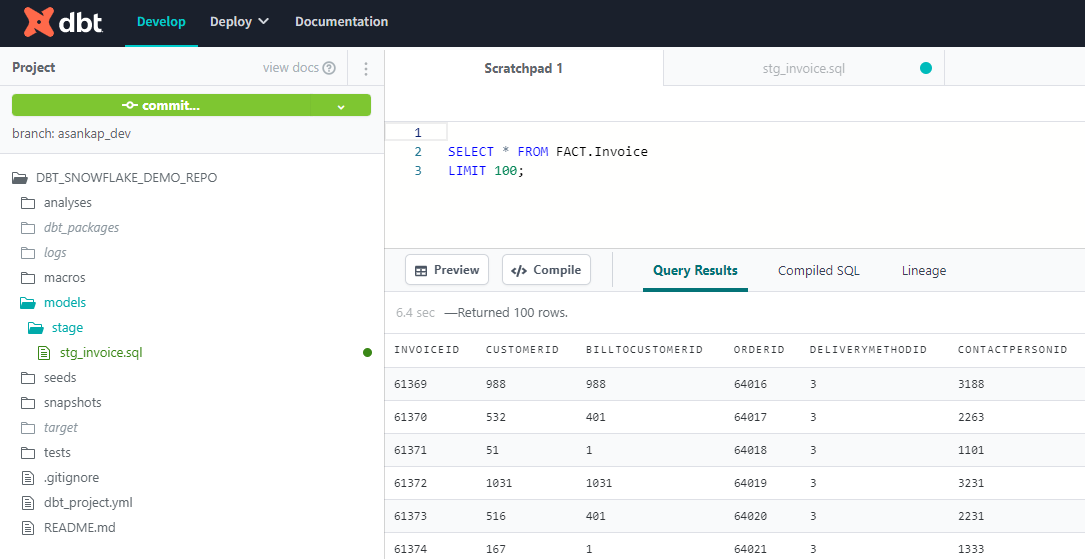
DBT Cloud provides a web-based development environment that facilitates multiple data engineers working simultaneously. Since DBT uses SQL language for the development and Common Table Expressions (CTEs) to break down complex business logic into smaller SQL modules as DBT models, data engineers can easily be onboarded into the development team as learning new languages is not required. Features such as custom materialisations, macro functions and the Jinja template language make development faster.
Within the DBT developer community, there are plenty of resources available to upskill a developer’s product knowledge. There are also a good set of pre-built packages provided by the community at no cost. These packages cover the most common data engineering patterns.
Build
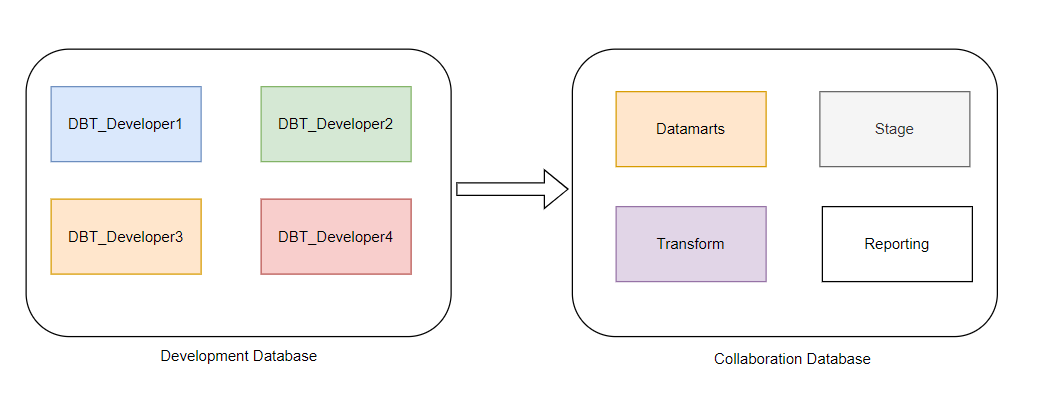
DBT Cloud allows transformation layers to be built rapidly. Each developer has their own development environment without any dependency on other developers. This is achieved by having a separate schema for each user in the development Snowflake database. A developer can build models and functions within his own development environment simply by running DBT commands. Each branch in the source control can be associated with a Snowflake database in DBT Cloud. This is called an environment. Once a developer completes a feature, their code is merged into a collaboration branch.
The collaboration branch is where multiple developers merge the code before it is moved into the Test or Dev-Test environment. Collaboration branch code can be built in a Snowflake database to validate and test how the merged code functions when multiple developers are working on a feature. Developer testing can be done in individual development environments as well as in the Collaboration Dev-Test database.
Environment Management
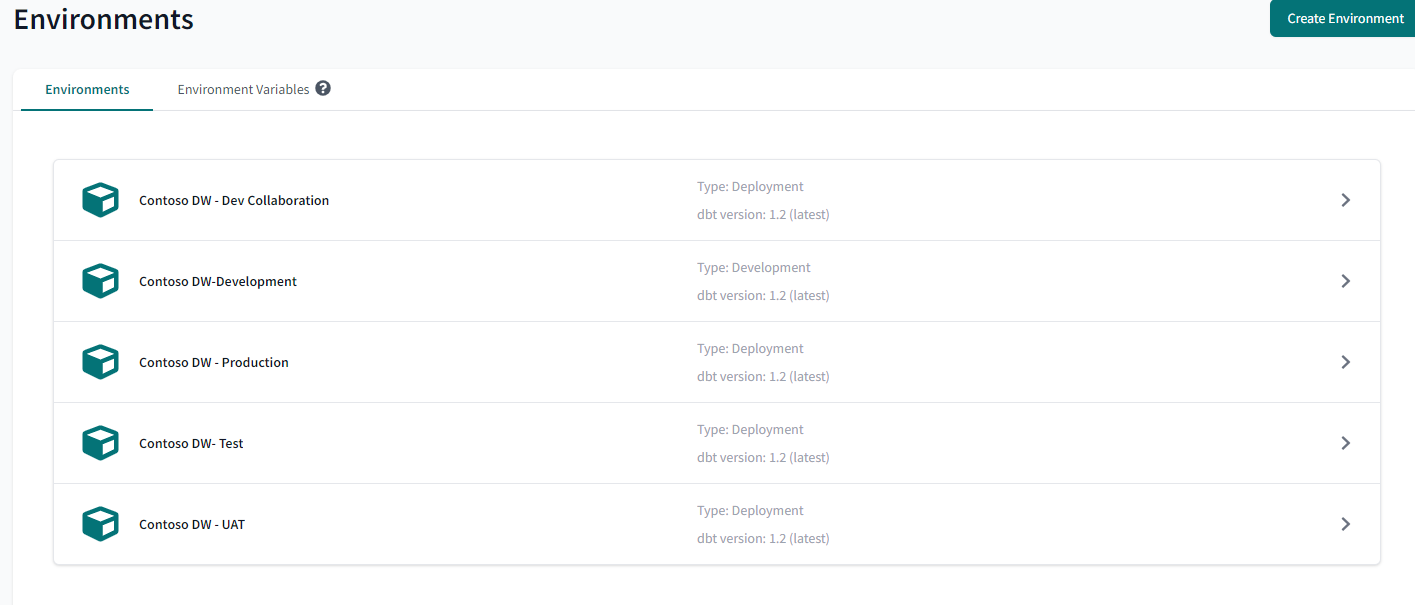
DBT Cloud allows the creation and management of multiple environments where each developer works in their own database schema. Each project must have one development environment, but depending on requirements, there can be any number of additional environments such as test, UAT, pre-prod, prod etc. Each environment is associated with a version control branch. With the support of environment variables, the behaviour of a DBT project can be customized from environment to environment.
Test
With DBT, one can perform both manual and automated testing. When it comes to automated testing, generic tests can be defined to cover common test scenarios such as checking for null, uniqueness of the data, and accepted values. To cover complex test cases, one can write singular tests within DBT. Singular tests are nothing but SQL select statements and any given test would fail if the select statement returns any records. Test cases can be defined to perform data validations in any stage of a data pipeline. For example, checking for nulls when staging data, and validating a calculation returns values within a defined range in the transform layer.
Release Management
In DBT Cloud, creating a release and managing a release is handled by implementing branches within the version control system. Currently DBT Cloud supports all the main version control systems such as GitHub, GitLab, Azure DevOps and Bitbucket. Each branch can be associated with an environment in DBT Cloud and since all the development is code-based, handling merge conflicts is straightforward. Once a developer completes a task, a pull request is created that will ultimately merge the code on the feature branch to the collaboration branch. Dev testing can be done in the collaboration database.
Once the dev testing is completed, the code on the collaboration branch is merged onto the test branch using a pull request and subsequent merge. The feature can then be moved to UAT, Pre-Production and Production using merge requests from one branch to another. One can also implement approval gates when progressing through the environments to production.
Deployment
Once the code is merged to a branch associated with an environment such as UAT, Pre-Production or Production, various DBT commands must be executed to deploy the code to the underlying Snowflake database. Some DBT commands such as “seed” and “docs” would typically be executed only once whereas some commands such as “test” and ”snapshot” have to be executed repeatedly. To achieve this, DBT has jobs that allow groups of DBT commands to run sequentially.
You can execute jobs manually, on a time schedule or based on a trigger. For example, in the event of a pull request or a merge request in the source code repository, Webhook triggers can run DBT jobs to build new and modified models as well as dependencies. Additionally, tools such as Apache Airflow, Perfect and Dagster have libraries that facilitate the execution of DBT jobs using DBT Cloud APIs.
Operate and Monitor
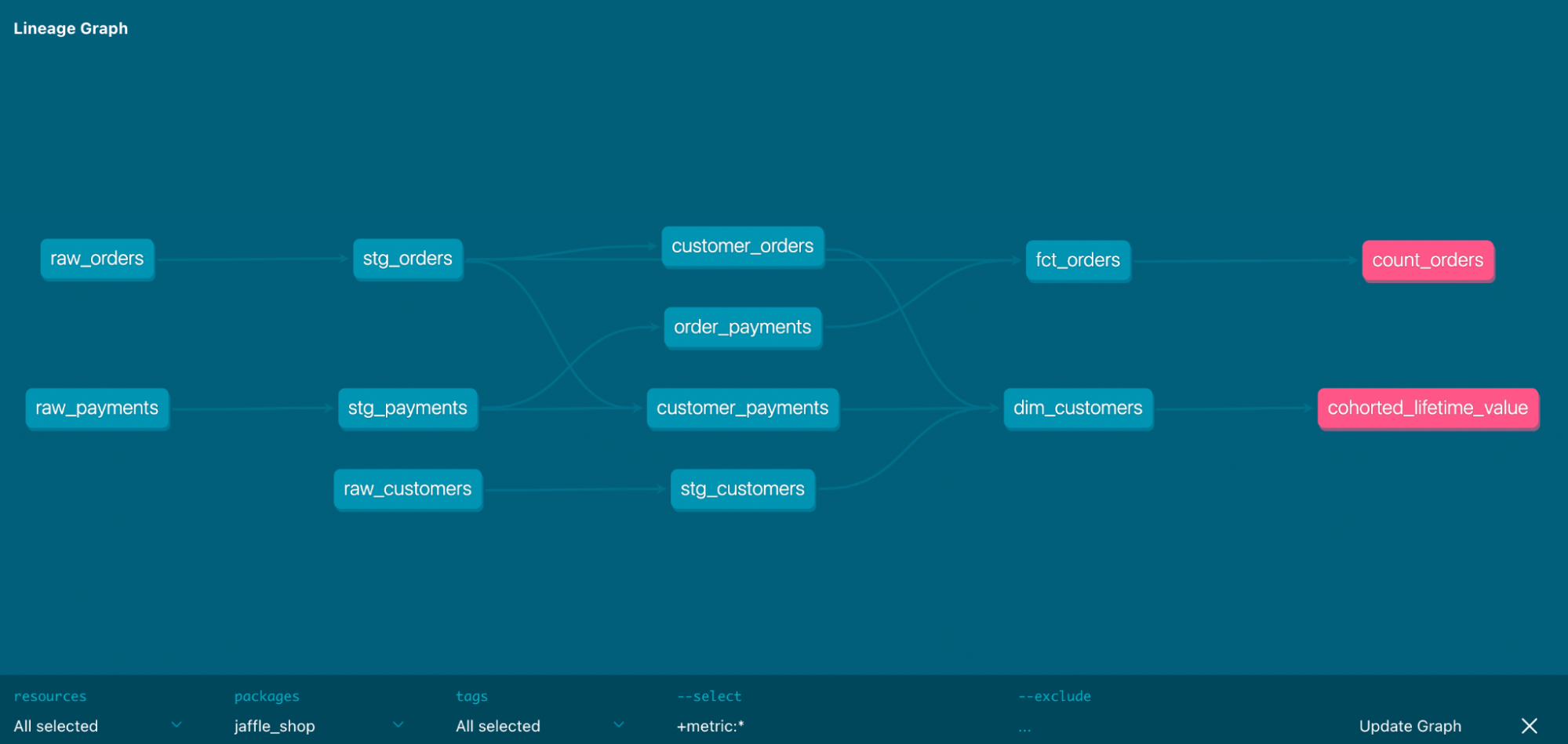
Once the deployment is complete, business users can start using the production Snowflake database via either views or tables for analytical purposes. Scheduled or triggered DBT jobs ensure that the data in Snowflake is being validated by running test cases. DBT Cloud offers documentation of models, schema and also creates directed acyclic graphs (DAG). Using DAG, users can understand the interdependencies between models and how transformations are done within different layers of the solution. Below is a diagram showing such a DAG.Snowflake supports various analytical tools such as Power BI, Tableau, Qlik, etc. Once the system is deployed in production, continuous monitoring to identify possible performance issues is a must.
Additionally, communication with business users is important to identify required changes to the solution. Snowflake has inbuilt dashboards and views to monitor warehouse performance and query performance. Additionally, Snowflake stores information about the query executions in history tables and these tables can be used to monitor the solution performance as well as how business users use the solution for various analytical requirements. There are also some pre-built reports from the community to monitor Snowflake usage.
Summary
DataOps supports faster implementation of data engineering solutions and is hence becoming a key aspect of any data engineering project. Key DataOps concepts can be easily applied to the DBT Cloud and Snowflake products. Features such as testing, automated deployment, version control and environment management available in DBT Cloud reduce the development cycle time and deliver outcomes to the business faster. Snowflake offers inbuilt capabilities to monitor and understand the usage pattern of a data warehouse solution.
At ClearPoint, we have a dedicated data engineering team comprised of experts who possess years of experience combined. Our data team supports clients to build modern data platforms following industry best practices. Our experts have been part of implementing major Snowflake and other data platform implementation projects across the Financial Services, Retail, Manufacturing and Government sectors.


