
Introduction
I really like this Tweet from YCombinator’s Paul Graham:
"The more inflated the language in your startup’s pitch, the less convincing it seems. If you’re a seed stage company, don’t tell me you’re transforming global this or poised to dominate that. Tell me you noticed something that might turn out to be an overlooked opportunity."
It tells us to be skeptical of bombastic claims and to look for small, overlooked opportunities. What humble opportunities might we find in the swirling mists of generative AI hype?
I have always been fascinated by the possibility of automated code migrations. Automated code migrations involve writing code to change code, exemplified by the work of infrastructure teams at Google and documented in Software Engineering at Google - Lessons Learned from Programming Over Time.
At ClearPoint, we have been able to perform basic automated migrations across large Kotlin/Java codebases using a tool called “lint” (previously Android Lint). This tool, used extensively at Google, sees the code from the perspective of an abstract syntax tree:
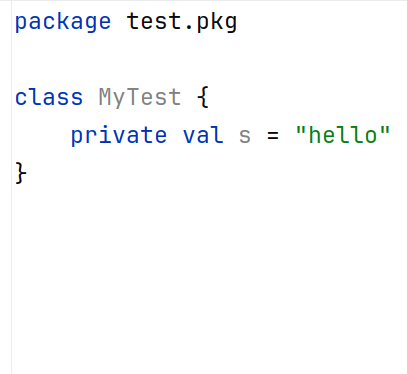
Code (left) with abstract syntax tree representation (right). Adapted from Android Lint API Guide
Within this tree-like structure, lint can see program information like names of functions, their parameters and their return type. Once we have this information, we can easily write custom lint rules to scan for common mistakes in our code. Lint can highlight these errors as we write code in the IDE, or it can generate an XML report with a list of rule violations that can be consumed by tools like Danger or SonarQube to provide automated pull request feedback.

An example of a lint warning (underlined in red) with a fix (“Add super call” in blue) surfaced in the IDE
Beyond inspecting our code as we write it, lint can also perform fixes. This is both available on an ad-hoc basis in the developer’s IDE where a suggestion appears in a tooltip and can be actioned immediately, and also via tooling where we can cause lint to produce a diff or alter code across one module or even an entire codebase.
As an example, we were able to author a lint rule for a large Kotlin codebase (over 20 active developers) that checked if Kotlin companion objects were declared at the end of the class file. This stopped the inconsistent pattern from being propagated further, but it did nothing about previous code files written in the old style, which were still prone to copy/paste into new code files. We extended our lint rule to include an auto-fix, and ran the tool over hundreds of files to produce patches to be merged into the codebase, cutting the issue off at the root.
|
|
|


Before and after, moving all Kotlin companion object declarations to the end of a file in a large codebase
The benefit from achieving consistency in this way should not be underestimated. It means that whenever a developer opens a file anywhere in the codebase they can expect to find the companion object declaration in the same place. Complexity is incremental so many small simplifications like this add up quickly.
Different codebase, different problem
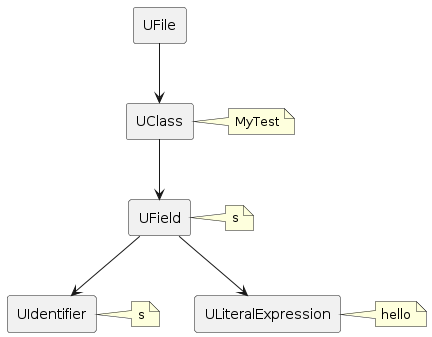
One of our clients wanted to enforce a new standard for unit testing. Previous unit test names were written in camel case, a style idiomatic for Java but less so for Kotlin.

An example of a test name in camel case in the old style
New test function names would take advantage of Kotlin backtick naming which allowed for spaces in the name. The convention would be “functionUnderTest - state - expected outcome” with the state being optional. To rewrite the above example in the new convention, we would name the test something like `invalidate - last auth successful within grace period - auth required`.
Turning to lint, we were able to write a rule that checked new tests were named following the convention. We did this by finding functions with the @Test annotation and extracting the name. We then scanned the name for backticks, the presence of two or three parts separated by hyphens, and capitalisation. This would warn developers if they went outside the convention for their new test cases.
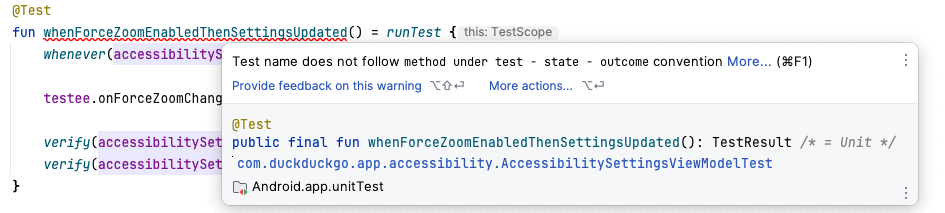
The lint warning warning of the old test case convention in the IDE
Now the question remained with what to do with the hundreds of test cases written in the old convention. These were problematic when some new functionality was added to an older Kotlin file. In this case, the new functionality would need to be covered by a test but writing a test in an old style would move achievement of the new standard further away. Writing one test in the new style would be inconsistent with the rest of the file. We tried asking intermediate developers to migrate the old test cases, but they would quickly become bored. Could we automate this tedious refactor?
Let’s consider what would happen if we started to write an auto-fix using lint to perform the renaming. In writing an algorithm for the computer to follow, we are confined to mathematical operations on the strings. This means procedures like sorting, reversing, splitting a camel-case string into its parts using a regular expression and so on. We have no way to tell the computer “read the code, work out what it is trying to say, and come up with a new name.”
Enter language models (LM). Of course, we cannot let the language model loose on our codebase to refactor. At best, this is wasteful in terms of token consumption. At worst, the language model will hallucinate and introduce coarse bugs. We would merely exchange time writing code for time correcting the language model output. The middle ground is to use lint to pinpoint the exact part of the code that needs to change (i.e., the test function name). We can then supply the LM with relevant context, obtain its suggestion, and use lint to safely apply the output to the codebase.
You might think of this approach as like keyhole surgery. We focus precisely using a rule-based engine (lint) on the part we want to change. Then we use a fuzzy engine (the language model) to obtain some kind of data beyond the ken of algorithms. We then turn back to rule-based lint to surgically transform the code in a safe way that avoids errors from hallucination and the problems of limited context windows.
This isn’t a new idea, the team behind Moderne and OpenRewrite have been doing amazing work in this area for a while:
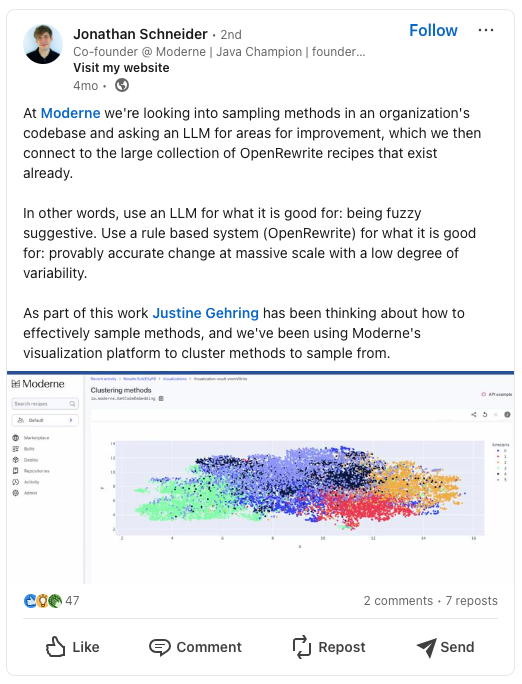
A post on LinkedIn from Moderne co-founder Jonathan Schneider putting forward the idea of combining rule-based and fuzzy tools
Applying the refactor
We wanted to explore the possibilities of this kind of refactor without revealing proprietary information. So we took the client’s test naming spec and attempted to apply it on a large open source project, the DuckDuckGo Android repo.
We needed to find a way to extend our convention-detecting lint rule to come up with test name suggestions by integrating with a language model. We chose to use langchain4j for the sake of convenience - it provides wrappers around common models like OpenAI, allowing us to easily swap models at a time when things are moving very fast.
In a project using lint, custom rules are included in the source code and are assembled into a jar for consumption by lint when it runs on the project. Using langchain4j in our custom lint rule required making an uber jar with the third-party dependencies included in the jar. We were able to follow the example in Slack’s lint repo to use John Rengelman’s Gradle shadow plugin for this purpose. While doing this, we were careful to watch the size of the jar to make sure it did not increase unreasonably.
DuckDuckGo lint-rules module showing the output jar. The jar contains the code to scan for JUnit tests as well as the code for talking to the LM
While the IDE and the build task use the same jar, we still want to restrict the use of the LLM to the latter to avoid harming IDE performance. We found out how to do this using cs.android.com, a tool provided by Google for searching through the public Android code. Lint already had the ability to make network calls via LintClient.openConnection. We speculated that these network calls would not happen while editing in the IDE since they could lead to a performance problem on the developer’s own machine. So we would look for such network-calling rules for examples of how to restrict our rule to batch mode (non-IDE). Luckily we were able to find an example of a public rule that did just this.
Armed with this knowledge, we wrote our rule and applied the fixes to one module in the codebase. This was to experiment quickly before rolling out to the entire set of modules. Our first attempt used llama2 running on Ollama. We used few-shot prompting (supplying a range of examples) but not a lot of care was put into choosing examples and the description of the refactor in the prompt was quite high-level:
The new standard for the names is `functionUnderTest - state - expected outcome`
Note that to meet the standard, the test names must have the following:
- They must be in backticks (``)
- They must have a minimum of two parts separated by a spaced hyphen “ - “
- The “state” is optional -it can be omitted
- The parts must start with lowercase if possible
After the explanation and examples, we used lint to fill in the prompt template with the body of the function we want to rename.
The combination of llama2 and the rough prompt led to poor results. In particular, within our convention “functionName - state - outcome” the model could not understand our instruction about the second part of the test convention and would regularly output test names with “state” in them:
|
Old test name |
Suggestion from llama2 |
Comment |
|
whenAutoSavedLoginIdSetButNoMatchingLoginFoundThenNewLoginSaved |
`createLoginForPrivateDuckAddress - auto saved login ID but no matching login found - new login saved` |
This is an adequate suggestion where the model correctly interprets the function under test and the state from the test body. |
|
whenSiteIsNotInNeverSaveListThenAutoSaveALogin |
`whenSiteIsNotInNeverSaveListThenAutoSaveALogin -ready to auto save - login saved` |
The model has not interpreted the function under test from the test body. |
|
whenEmptyInputThenEmptyListOut |
`whenEmptyInputThenEmpty ListOut - state - expected outcome` |
The model has not interpreted the state or expected outcome from the function body and just substituted meaningless words into the test name. |
Using Open AI’s gpt-3.5-turbo model led to results that avoided many of these errors and was very fast, completing the refactor in just 28 seconds with a cost of $0.02 USD. However, in an embarrassment of riches for our prototype, llama3 was released on April 18, 2024. By this time we had refined our prompt based on common mistakes from previous models, including an extremely detailed description of what we were aiming for:
The new standard for the names is:
`methodUnderTest - state - expected outcome`
Here:
- “methodUnderTest” means the method that the test intends to exercise. If we’re thinking of “arrange/act/assert” then the method under test is normally exercised in the “act” part of the test body i.e., the middle.
- The “state” means the setup or situation for the test. Thinking of “arrange/act/assert” the state would normally be the first part. Note that not all tests have state. For instance, tests with no set up or tests of pure functions.
- “Expected outcome” means what we are hoping to measure in the test. Thinking of “arrange/act/assert” this would be the “assert” part (the last part of the test)
The combination of llama3 (even the quantized 8B parameter model) and the verbose, almost pedantic prompt rendered much better results. However we still ran into a few edge cases where the model output a name that contained periods and was thus illegal for Kotlin:
`isAutofillEnabledByUser - user enabled - ${testCase.scenario}`
When analysing, we found that the root of the problem here was the model attempting to rename parameterized JUnit tests which have a different naming convention. Rather than tweak the prompt further to account for this, we turned to lint to exclude parameterized tests from the refactor and performed a simple replace of ‘.’ with ‘·’ to account for other edge cases (like test names that included sample IP addresses).
In one generated diff, the language model supplied the same function name twice within one file. This causes the “conflicting overloads” Kotlin compilation error. The simplest thing to do here is to maintain a table of names received from the model and reject names that have already been seen.
These cases reiterate the power of combining rule-based engines with fuzzy models - when we encounter an edge case where the language model falls down, we can simply exclude it from our migration. Although this means that a human will eventually have to finish the job, this is a realistic expectation given the inherent limitations of LLMs and the balance between the time spent engineering the automated migration versus the time performing the migration manually.
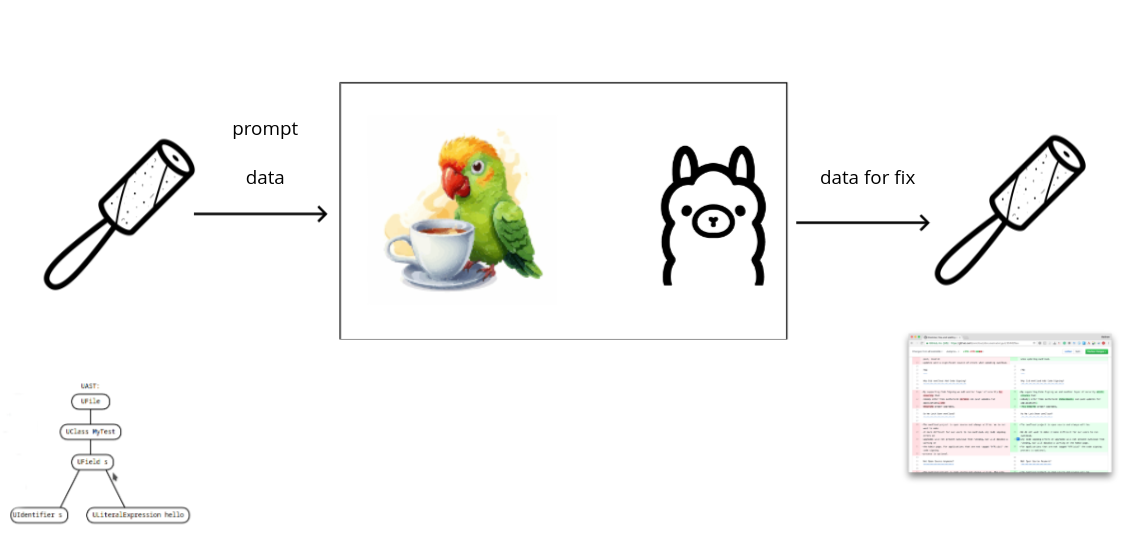
Final architecture for our AI-assisted refactor
Evaluating the refactor
We ran the automated refactor across all the modules in the DuckDuckGo project that followed the `android-library.gradle` build convention.
|
Language model |
llama3:8b (a6990e) |
|
Scaffolding for refactor (lines of code) |
Approx. 500 |
|
Time taken |
43 min 31 seconds |
|
Test files migrated to new convention |
517 |
|
Lines of code changed in migration |
4417 |
The scaffolding for the refactor refers to the custom lint rule that talks to the LM i.e., the code to fix the code. When run using Gradle, it will perform the code changes for us and we can simply commit the result and submit it as a pull request. You can review the generated diff on GitHub here. Despite the effort spent devising the prompt and accounting for edge cases, there are still some errors that would require correction in review. However, the thrust of the pull request is correct and the volume is impressive.
We had experience with manually performing this kind of refactor for a client. Choosing good names wasn’t easy and it could take an hour for a senior engineer to rename, say, ten test cases. That would mean our generated pull request represents approximately 440 engineering hours, or 11 engineering weeks of work.
While significant time was spent experimenting with lint to find a way to safely integrate language models, this effort carries over for the next set of automated migration. The test renames are just one example of an automated refactor that would not have been possible before large language models became popular. Codebases often end up with inconsistent naming of one kind or another and there is often not enough time to scan the codebase and go back and fix old code.
Beyond simple naming problems, in the future we can attempt other categories of change where the migration itself is simply too difficult to describe algorithmically. This means situations where the cost of devising the algorithm and working around edge cases is much greater than the cost of reviewing and correcting a flawed LM-generated diff.
Summary
- Rule-based engines provide guardrails for language models and have opened the way for new categories of automated migrations as shown in existing tools from OpenRewrite and Moderne.
- Lint is a powerful tool in the JVM ecosystem. Lint’s code scanning and fixing capabilities can be extended via integration with language models.
- Managing an LM-assisted migration involves crafting careful examples and explanations for the prompt and working around limitations of LM using rules.
- These migrations benefit from more sophisticated language models as shown in the difference in quality between llama2 and llama3.
- LMs can be integrated in a way that does not risk intellectual property or cloud vendor lock-in using local tools like Ollama.
We will help you to realise the potential of AI and streamline the potential to meet your unique business needs. Find out more.



